Google asserts that it handles “most of the hard work to protect” the security of containers within their cloud for customers. Meanwhile, Amazon claims that “serverless is one of the hottest design patterns in the cloud today, allowing you to focus on building and innovating, rather than worrying about the heavy lifting of server and OS operations.”
Software engineering teams often face the dilemma of choosing between serverless and container architecture, determining which approach best suits their needs. As the head of engineering at Machines And Cloud, I encourage our teams to evaluate and leverage new technologies when they can enhance our products and improve their security. As a software security company, we place particular emphasis on the security aspects of the technologies we use and develop ourselves.
There are numerous online articles claiming that containers provide greater flexibility, especially when migrating legacy services to the cloud. However, serverless is often preferred for its rapid development, scalability, and reduced runtime costs.
We decided that the most effective way to validate or refute conventional wisdom was to directly compare serverless and container architectures in a real-world scenario of building a microservice. We aimed to understand five key aspects of these technologies, including ease of use, cost, scalability, security, and time to market. This article documents our experience and summarizes what we learned from the experiment.
Our use case for the architecture comparison:
We tested a serverless architecture using Google Cloud Function and a container architecture using Google Kubernetes Engine to build a microservice that would become a component of our commercial software product, Brand Protect. We sought to compare the five factors mentioned earlier and choose our preferred architecture based on the results.
Machines And Cloud’s product, Brand Protect, detects cloned versions of our customers’ mobile applications that have been illegitimately placed in alternative app stores worldwide. Our customers didn’t authorize these placements and would want the apps removed.
Our product identifies these illicit listings using various machine-learning techniques, captures a screenshot of the fraudulent and unauthorized app listing in the app store, and sends that evidence in an automated takedown request.
In this context, we designed a microservice to compare the two architectures. The microservice would visit a specified app store URL, take a screenshot, and store the image for further machine-learning-based processing to determine whether an automated takedown request was necessary.
Scalability is a crucial factor in this process, as we perform these actions hundreds of thousands of times per day, and as more customers use our product, the microservice must be able to accommodate growth.
Our experience with a serverless architecture:
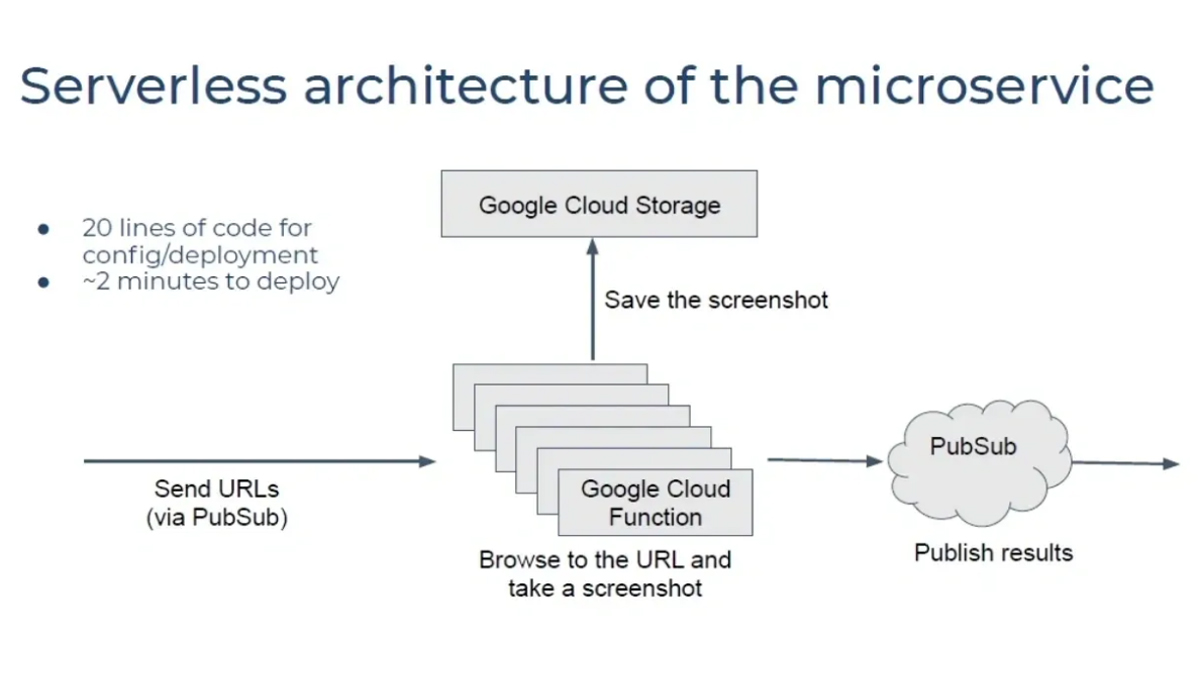
Initially, we tried the serverless architecture. The service running on Google Cloud Function received a URL to browse, captured a screenshot of the page, and stored the image on Google Cloud Storage. Once completed, the service published results to a PubSub queue, notifying a subsequent service that the image was ready.
We found that deploying every component of this architecture took about two minutes, while writing the code to configure everything took approximately 20 minutes. Our initial impression was that serverless was straightforward to design and deploy, with minimal infrastructure or configuration knowledge required. However, the downside is the vendor lock-in, as the architecture is entirely tied to Google Cloud and cannot be easily migrated to another provider.
Exploring a container architecture:
After the serverless prototype, we tested a container strategy for the same microservice, using Google Kubernetes Engine (GKE) on Google Cloud. Similar to the serverless approach, the service began by receiving the URLs to visit and take screenshots of any unauthorized app listings. The browsing process occurred in a container, with the screenshot saved to a virtual disk automatically mounted to the worker instance running the container. The results were then published to a Redis list.
Deploying this architecture and setting it up took about 10 minutes, requiring approximately 200 lines of code for deployment and configuration of each container node. Thus, the setup took five times longer than serverless, and coding required ten times more effort for this architecture. Initially, we were overwhelmed by the numerous options, customization possibilities, and configurations available. It was impressive to have control over every container, VM, RAM, disk space, and network layout.
Moreover, there is no vendor lock-in with this approach. Nothing in this architecture is specific to Google Cloud, allowing for easy migration to another cloud provider.
A comprehensive analysis:
To provide a more thorough comparison, we created a real-world test scenario that involved processing 200,000 screenshot tasks per day. Each task was memory-intensive because we had to run Chrome as a headless browser, necessitating a virtual server architecture with ample RAM.
For the serverless architecture, we ran only one task per function, and for the container architecture, we ran only one task per container. This allowed us to allocate enough RAM for just running the browser and capturing the screenshot.
Additionally, we distributed the workload throughout the day, sending about 5,000 tasks every hour instead of creating a large spike in tasks all at once. We could do this because our microservice didn’t have strict real-time requirements: the screenshots were not needed immediately, and it was acceptable to spread the workload throughout the day. This use case mirrors any kind of background batch processing and is not specific to our test case. Distributing the workload in this manner allowed us to maintain a high enough average utilization of the container cluster to avoid idle periods, which can lead to inefficiencies and higher costs.
Lessons on Scaling
When examining scaling, we found that serverless has the advantage of scaling down to zero instances, meaning you don’t pay for anything when no work is happening. It also scales up quickly when there is work to do. However, despite the promise of not needing to manage scaling with serverless, we realized that managing scaling is still necessary in the real world due to external dependencies and APIs not scaling in the same way. In our case, accessing a website with a thousand functions crawling it at once could lead to an unintentional denial of service (DoS) attack. Additionally, hitting quotas on Google Cloud operations can cause subsequent Cloud Function invocations to fail. Nonetheless, serverless offers better global scalability than anything we’ve seen in private data centers or public cloud infrastructure.
With the container architecture and Kubernetes Engine, some VMs are always running, and figuring out scaling takes more work. However, this approach provides more control and options for scaling. Determining scaling with containers takes more initial effort, but the cost is more predictable, and the level of effort to maintain this architecture is non-trivial.
Advantage: Serverless
Cost
Surprisingly, the serverless approach was 10 times more expensive than the container approach, costing about $20 a day with Google Cloud Function compared to about $2 a day for the container architecture. There are hidden costs with the GKE architecture, such as needing an engineer to manage and monitor the cluster and perform maintenance. The cost advantages may differ depending on the types of applications being built. For time-sensitive or real-time applications with varying workloads, serverless may be more cost-effective. However, for our batch processing use case, the container-based architecture saved us more money.
Advantage: Containers
Security
Security for serverless involves securing only the application code since the infrastructure is managed by the cloud provider. In contrast, applying security to containers is more complex, involving securing container images, encrypting the network between nodes, and securing VMs and guest operating systems. Additionally, the container runtime (such as Kubernetes) must be maintained. Serverless has a smaller attack surface, with the most critical aspect being the exposed APIs within the application code. Innovative services, like Data Theorem’s API Discover and API Inspect, are available to help with these security challenges. Generally, securing infrastructure tiers of containers requires more effort and potential costs compared to serverless.
Advantage: Serverless
Summary
For our microservice use case, we found that the serverless Google Cloud Function implementation was better suited to our needs, offering convenience, ease of setup, security, scalability, deployment, and iteration. These advantages outweighed the cost disadvantage for us, as our startup needed to deliver products quickly and reduce complexity at the infrastructure management layer.
However, the 10x cost difference made us consider using Google Kubernetes Engine for some projects where the GCP bill may rise due to Cloud Functions pricing. This would involve significant re-architecting and increased maintenance costs, but portions of the cloud bill could be reduced.
Ultimately, both serverless and containers offer benefits to software engineering. It is essential to perform your comparison using your use case to determine how they fit into your software development program.